
Appearance
Consumer消费者实战
Kafka中的消费者组
Kafka以分区纬度消费消息
- 一个分区只可以被消费组中的一个消费者所消费。
- 一个消费组中的一个消费者可以消费多个分区,例如 C1 消费了
P0,P3。 - 所有消费者一起消费所有的分区,例如 C1 和 C2 共同完成了对 P0、P1、P2、P3 的消费。
- 在不同消费组中,每个消费组都会消费所有的分区,例如消费组A、消费组B都消费了P0、P1、P2、P3。
- 同一个消费组里面的消费者对分区是互斥的,例如 C1 和 C2 不会消费同一个分区;而分区在不同的消费组间是共享的。
- 如果分区数小于消费者数量,多余的消费者将处于空闲状态,不会消费消息。

TIP
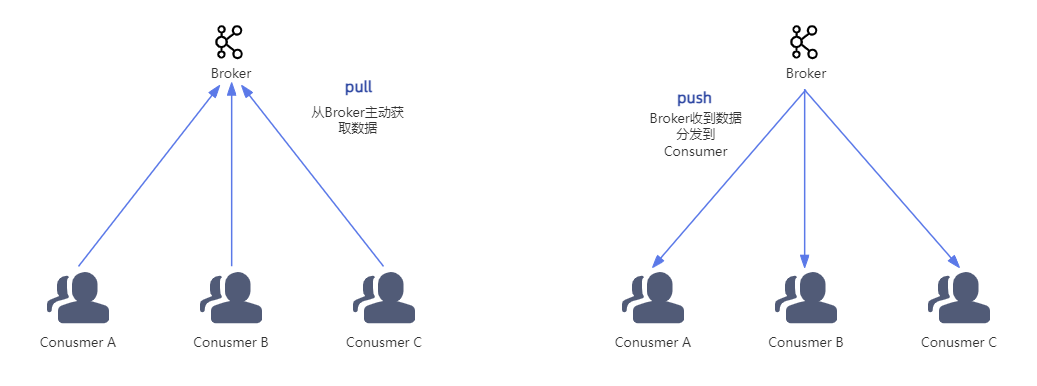
消费者从Broker获取数据通常采用的是"pull"(拉取)模式。在这种模式下,消费者通过主动向Broker发送请求来获取数据。
为什么使用pull模式?
首先,pull模式能够根据消费者的消费能力进行调整,比如有三台机器,A机器配置高处理能力强,另外两台弱一些,在消费完本次数据后就主动向Broker“要”数据,实现机器消费能力自适应;
如果使用broker主动push的方式,当消息量非常大时,消费者可能会无法及时处理这些推送过来的消息。这样会导致消息堆积,影响系统的稳定性和性能。而使用pull模式,消费者可以根据自身的处理能力合理地控制数据的获取速度,避免消息的积压。
使用push模式等于是Broker向消费者发送消息,Broker没法知道消费者对之前消息的处理情况,也就无法实现自适应功能。
此外,如果broker没有数据可供消费者获取时,消费者可以通过配置超时时间来进行阻塞等待。当有新的消息到达时,消费者会立即获取到这些消息并进行处理。
SpringBoot关闭Kafka日志
logback.xml
xml
<configuration>
<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
<encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder">
<!-- 格式化输出: %d表示日期, %thread表示线程名, %-5level: 级别从左显示5个字符宽度 %msg:日志消息, %n是换行符 -->
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS}[%thread] %-5level %logger{50} - %msg%n</pattern>
</encoder>
</appender>
<root level="info">
<appender-ref ref="STDOUT"/>
</root>
</configuration>application.yml
yaml
logging:
config: classpath:logback.xml消费者配置
properties
#消费者分组ID,分组内的消费者只能消费该消息一次,不同分组内的消费者可以重复消费该消息
group.id
#为true则自动提交偏移量
enable.auto.commit
#自动提交offset周期
auto.commit.interval.ms
#重置消费偏移量策略,消费者在读取一个没有偏移量的分区或者偏移量无效情况下(因消费者长时间失效、包含偏移量的记录已经过时并被删除)该如何处理,
#默认是latest,如果需要从头消费partition消息,需要改为 earliest 且消费者组名变更 才可以
auto.offset.reset
#序列化器
key.deserializerJavaApi配置如下
java
private Properties getKafkaConfigProperties() {
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, xk857ProducerMqService.getEndpoint());
// 消费者分组ID,分组内的消费者只能消费该消息一次,不同分组内的消费者可以重复消费该消息
props.put("group.id", "xk857-g1");
// 开启自动提交offset
props.put("enable.auto.commit", "true");
// 自动提交offset延迟时间
props.put("auto.commit.interval.ms", "1000");
// 反序列化
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
return props;
}消费者消费消息
java
@Test
public void simpleConsumerTest(){
Properties props = getKafkaConfigProperties();
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
// 订阅topic主题
consumer.subscribe(Arrays.asList(TopicEnums.GE_TUI_MESSAGE.getValue()));
while (true) {
//拉取时间控制,阻塞超时时间
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(500));
for (ConsumerRecord<String, String> record : records) {
System.err.printf("topic = %s, offset = %d, key = %s, value = %s%n",record.topic(), record.offset(), record.key(), record.value());
}
}
}消费者分配策略
- Range(默认):范围分配,将每个 Topic 的分区按顺序划分范围。
- 简单易实现。
- 可能导致分配不均(尤其 Topic 数量多时,前面的消费者负载偏高)。
- RoundRobin:轮询分配,将所有 Topic 的分区按哈希排序后轮询分配给消费者。
- 分配更均衡。
- 要求所有消费者订阅相同的 Topic 列表。
- Sticky:粘性分配。
- 初始分配类似 RoundRobin,但再平衡(Rebalance)时尽量保留原有分配,减少分区迁移。
- 减少再平衡时的数据迁移,提升稳定性。
- 需配合
partition.assignment.strategy使用。

java
Properties props = new Properties();
// 设置 Range 分配策略
props.put("partition.assignment.strategy", "org.apache.kafka.clients.consumer.RangeAssignor");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(List.of("topic1", "topic2")); // 订阅主题列表java
Properties props = new Properties();
// 设置 RoundRobin 分配策略
props.put("partition.assignment.strategy", "org.apache.kafka.clients.consumer.RoundRobinAssignor");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
// 所有消费者必须订阅相同的Topic
consumer.subscribe(List.of("topic1","topic2"));java
Properties props = new Properties();
// 设置 Sticky 分配策略
props.put("partition.assignment.strategy", "org.apache.kafka.clients.consumer.StickyAssignor");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(List.of("topic1", "topic2"));DANGER
同一个消费者组的分配策略必须是一致的,